一、概念解释:
ANSI:并不是某一种特定的字符编码。在不同的系统中,ANSI表示不同的编码(美国同事的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码)
windows系统通过Windows code pages的值来确定当前系统的编码方式(ANSI只存在于Windows系统,不同地区发行的系统,ANSI指代不同)
编码规范和具体编码
字符编码:
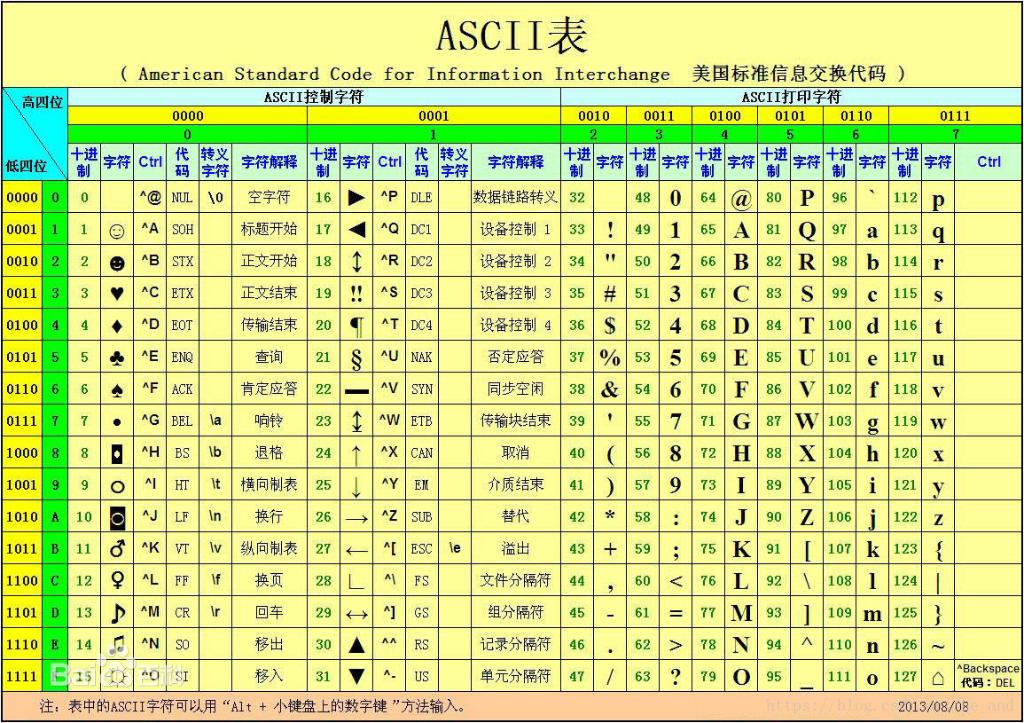
1、ASCII编码:早期计算机(美国人造的),用ascii编码(一个字节,8位,可以表示256个编码,实际英语世界里字母、数字和常用符号完全够用)
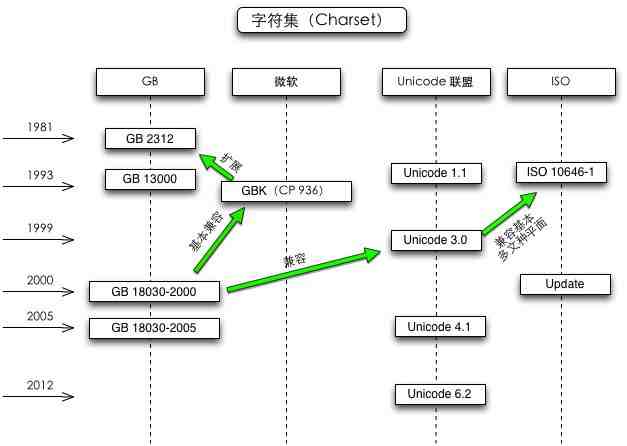
2、后来,中国人使用计算机,256不够用,中国国家标准总局1980年发布--GB2312。台湾--Big-5
其中收录了6763个常用汉字和682个其它符号(6763+682=7445),并将该字符集分为94个区,每个区94位,每个位对应一个字符或零个字符(94x94=8836,8836-7745=1391说明有1391个位置是空的)
但通常,人们所说的GB2312指的是一种编码(并且不是指区位码),它是指通常采用EUC方法对GB2312字符集中的“区”和“位”进行处理后的编码。
3、继续扩展,之前GB2312中没有利用的位--GBK(又增加了2万多个汉字,GBK是从GB2312扩展而来的,支持繁体,并且兼容GB2312)
4、继续扩展,少数民族语言 -- GB18030
GB2312和GBK都是用两个字节来编码的,就算用完所有的位(256*256=65536)也不够为所有的汉字编码。于是就有了目前最新的GB18030,它采用类似UTF-8的编码方式进行编码(每个字符的编码可以是 1、2或4个字节),拥有上百万个编码空间,足以支持中日韩三国所有汉字,并且还可以支持国内少数民族的文字
Unicode编码
Unicode只是简单的字符到数字的一个映射,就相当于一个电话本,它是没有字节限制的,是可以无限表示的,它也不管一个字符在计算机中式怎么存储的,具体怎么存储涉及到字符编码,而unicode应该叫做字符集
Unicode为世界上的每一个字符都弄了一个对应的数字,所以就不会再存在乱码问题了,比如,汉字“严”的Unicode是十六进制数 4E25 ,转换成二进制数足足有15位( 100111000100101 )
也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号, 可能需要3个字节或者4个字节,甚至更多,这里会出现几个问题:
**A.**我们怎么知道是三个字节一起表示一个字符,还是说三个字节分别表示三个字符
**B.**之前一个ascii字符只需要一个字节,但是现在用了unicode普遍使用三个或四个字节,那使用英文就回浪费很多字节
于是针对unicode出现了很多不同的编码方案,这些方案就是为了解决unicode在计算机中具体怎么存储的问题
经常听说的有:utf-8、utf-16、utf-32
utf-16是用两个或四个字节表示一个字符
utf-32使用四个字节表示一个字符
而utf-8是可变长的编码方案,它可以用1~4个字节表示不同字符,显而易见,前面两种编码方案会浪费很多字节,而utf-8就很好了,所以我们现在也通常使用utf-8
UTF-8编码:
1)对于单字节的符号,字节的第一位设为 0 ,后面7位为这个符号的 Unicode 码。因此对于 英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于 n 字节的符号( n > 1 ),第一个字节的前 n 位都设为 1 ,第 n + 1 位设为 0 ,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
根据utf-8的编码规则,我们就可以发现它很好的解决了前面的两个问题:
兼容ascii且不适用多余的字节,多字节的字符,我们可以通过判断它的第一个字符来确定字节数。
这是一份编码表,其中xxx处填写相应的unicode值

举个例子:
“侠”的unicode表示是4fa0,根据上表我们来计算一下它的utf-8编码:
根据上表,4fa0在第三行的位置,也就是我们需要把unicode值依次填入1110xxxx 10xxxxxx 10xxxxxx中,开始填字游戏吧:
11100100 10111110 10100000
转换为16进制后:E4BEA0
=整理自互联网
参考地址:https://blog.csdn.net/he_and/article/details/80380084
==
Copyright © 2015 - 2016 DISPACE.NET | 使用帮助 | 关于我们 | 投诉建议